 My research centers on advancing the acquisition and interpretation of visual data through image processing, machine learning, and computational modeling. I specialize in creating technologies for the automatic construction of digital twins from remote sensing data, with a focus on Earth observation. This work is driven by the need to tackle global challenges, including disaster management and environmental assessments, thereby enhancing decision-making processes. My goal is to develop innovative solutions that improve our understanding and interaction with the world, contributing to sustainable and resilient societal development.
My research centers on advancing the acquisition and interpretation of visual data through image processing, machine learning, and computational modeling. I specialize in creating technologies for the automatic construction of digital twins from remote sensing data, with a focus on Earth observation. This work is driven by the need to tackle global challenges, including disaster management and environmental assessments, thereby enhancing decision-making processes. My goal is to develop innovative solutions that improve our understanding and interaction with the world, contributing to sustainable and resilient societal development.
Intelligent Imaging and Inverse Problems
By integrating sensing and computation, we aim to extract information that cannot be captured by hardware alone, overcoming limitations such as resolution, noise, and occlusion. We develop mathematical models and algorithms grounded in machine learning, optimization, and signal processing to reconstruct original signals or scenes from incomplete or noisy observations.Related publications
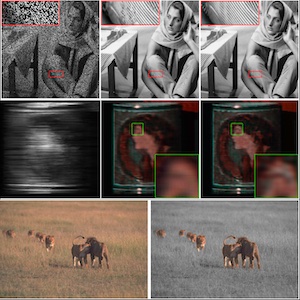 | W. He, T. Uezato, and N. Yokoya, ”Interpretable deep attention prior for image restoration and enhancement,” IEEE Transactions on Computational Imaging, vol. 9, pp. 185-196, 2023. PDF Quick Abstract Abstract: An inductive bias induced by an untrained network architecture has been shown to be effective as a deep image prior (DIP) in solving inverse imaging problems. However, it is still unclear as to what kind of prior is encoded in the network architecture, and the early stopping for the overfitting problem of DIP still remains the challenge. To address this, we introduce an interpretable network that explores self-attention as a deep attention prior (DAP). Specifically, the proposed deep attention prior is formulated as an interpretable optimization problem. A nonlocal self-similarity prior is incorporated into the network architecture by a self-attention mechanism. Each attention map from our proposed DAP reveals how an output value is generated, which leads to a better understanding of the prior. Furthermore, compared to DIP, the proposed DAP regards the single input degraded image as input to reduce the instability, and introduces the mask operation to handle the early stopping problem. Experiments show that the proposed network works as an effective image prior for solving different inverse imaging problems, such as denoising, inpainting, or pansharpening, while also showing potential applications in higher-level processing such as interactive segmentation and selective colorization. |
 |
X. Dong, N. Yokoya, L. Wang, and T. Uezato, ”Learning mutual modulation for self-supervised cross-modal super-resolution,” Proc. ECCV, 2022. PDF Quick Abstract Abstract: Self-supervised cross-modal super-resolution (SR) can overcome the difficulty of acquiring paired training data, but is challenging because only low-resolution (LR) source and high-resolution (HR) guide images from different modalities are available. Existing methods utilize pseudo or weak supervision in LR space and thus deliver results that are blurry or not faithful to the source modality. To address this issue, we present a mutual modulation SR (MMSR) model, which tackles the task by a mutual modulation strategy, including a source-to-guide modulation and a guide-to-source modulation. In these modulations, we develop cross-domain adaptive filters to fully exploit cross-modal spatial dependency and help induce the source to emulate the resolution of the guide and induce the guide to mimic the modality characteristics of the source. Moreover, we adopt a cycle consistency constraint to train MMSR in a fully self-supervised manner. Experiments on various tasks demonstrate the state-of-the-art performance of our MMSR. |
 |
T. Uezato, D. Hong, N. Yokoya, and W. He, “Guided deep decoder: Unsupervised image pair fusion,” Proc. ECCV (spotlight), 2020. PDF Supmat Code Quick Abstract Abstract: The fusion of input and guidance images that have a tradeoff in their information (e.g., hyperspectral and RGB image fusion or pansharpening) can be interpreted as one general problem. However, previous studies applied a task-specific handcrafted prior and did not address the problems with a unified approach. To address this limitation, in this study, we propose a guided deep decoder network as a general prior. The proposed network is composed of an encoder-decoder network that exploits multi-scale features of a guidance image and a deep decoder network that generates an output image. The two networks are connected by feature refinement units to embed the multi-scale features of the guidance image into the deep decoder network. The proposed network allows the network parameters to be optimized in an unsupervised way without training data. Our results show that the proposed network can achieve state-of-the-art performance in various image fusion problems. |
Scene Understanding and Multimodal Fusion
To understand complex real-world scenes, we develop methods that combine data from diverse sensors—including optical, thermal, depth, and LiDAR—captured from various platforms. Our research includes semantic and 3D reconstruction, digital twin generation, and efficient learning from limited or noisy supervision. We are also expanding into vision-language models to enable more generalizable and interactive understanding of such scenes. To address data scarcity, we explore simulation-based training and synthetic data generation.Related publications
 |
W. Gan, N. Mo, H. Xu, and N. Yokoya, ”A comprehensive framework for 3D occupancy estimation in autonomous driving,” IEEE Transactions on Intelligent Vehicles, 2024. PDF Quick Abstract Abstract: The task of estimating 3D occupancy from surrounding view images is an exciting development in the field of autonomous driving, following the success of Birds Eye View (BEV) perception.This task provides crucial 3D attributes of the driving environment, enhancing the overall understanding and perception of the surrounding space. However, there is still a lack of a baseline to define the task, such as network design, optimization, and evaluation. In this work, we present a simple attempt for 3D occupancy estimation, which is a CNN-based framework designed to reveal several key factors for 3D occupancy estimation. In addition, we explore the relationship between 3D occupancy estimation and other related tasks, such as monocular depth estimation, stereo matching, and BEV perception (3D object detection and map segmentation), which could advance the study on 3D occupancy estimation. For evaluation, we propose a simple sampling strategy to define the metric for occupancy evaluation, which is flexible for current public datasets. Moreover, we establish a new benchmark in terms of the depth estimation metric, where we compare our proposed method with monocular depth estimation methods on the DDAD and Nuscenes datasets.The relevant code will be available in this https URL. |  |
Z. Liu, Y. Li, F. Tu, R. Zhang, Z. Cheng, and N. Yokoya, ”DeepTreeSketch: Neural graph prediction for faithful 3D tree modeling from sketches,” Proc. CHI, 2024. Project Page Video Quick Abstract Abstract: We present DeepTreeSketch, a novel AI-assisted sketching system that enables users to create realistic 3D tree models from 2D free- hand sketches. Our system leverages a tree graph prediction net- work, TGP-Net, to learn the underlying structural patterns of trees from a large collection of 3D tree models. The TGP-Net simulates the iterative growth of botanical trees and progressively constructs the 3D tree structures in a bottom-up manner. Furthermore, our system supports a flexible sketching mode for both precise and coarse control of the tree shapes by drawing branch strokes and foliage strokes, respectively. Combined with a procedural genera- tion strategy, users can freely control the foliage propagation with diverse and fine details. We demonstrate the expressiveness, effi- ciency, and usability of our system through various experiments and user studies. Our system offers a practical tool for 3D tree cre- ation, especially for natural scenes in games, movies, and landscape applications. |
 |
X. Dong and N. Yokoya, ”Understanding dark scenes by contrasting multi-modal observations,” Proc. WACV, 2024. PDF Code Quick Abstract Abstract: Understanding dark scenes based on multi-modal image data is challenging, as both the visible and auxiliary modalities provide limited semantic information for the task. Previous methods focus on fusing the two modalities but neglect the correlations among semantic classes when minimizing losses to align pixels with labels, resulting in inaccurate class predictions. To address these issues, we introduce a supervised multi-modal contrastive learning approach to increase the semantic discriminability of the learned multi-modal feature spaces by jointly performing cross-modal and intra-modal contrast under the supervision of the class correlations. The cross-modal contrast encourages same-class embeddings from across the two modalities to be closer and pushes different-class ones apart. The intra-modal contrast forces same-class or different-class embeddings within each modality to be together or apart. We validate our approach on a variety of tasks that cover diverse light conditions and image modalities. Experiments show that our approach can effectively enhance dark scene understanding based on multi-modal images with limited semantics by shaping semantic-discriminative feature spaces. Comparisons with previous methods demonstrate our state-of-the-art performance. Code and pretrained models are available at https://github.com/palmdong/SMMCL. |
Remote Sensing for Societal Impact
Remote sensing enables us to observe large-scale and inaccessible regions of the Earth, playing a vital role in addressing global challenges. We develop intelligent information processing techniques to extract land cover, elevation, biomass, and urban structure from satellite and aerial imagery. Applications include disaster damage assessment, forest carbon stock estimation, agricultural monitoring, and environmental change detection.Related publications
 |
J. Song, H. Chen, W. Xuan, J. Xia, and N. Yokoya, ”SynRS3D: A synthetic dataset for global 3D semantic understanding from monocular remote sensing imagery,” Proc. NeurIPS D&B Track (spotlight), 2024. Project Page PDF Code Quick Abstract Abstract: Global semantic 3D understanding from single-view high-resolution remote sensing (RS) imagery is crucial for Earth Observation (EO). However, this task faces significant challenges due to the high costs of annotations and data collection, as well as geographically restricted data availability. To address these challenges, synthetic data offer a promising solution by being easily accessible and thus enabling the provision of large and diverse datasets. We develop a specialized synthetic data generation pipeline for EO and introduce SynRS3D, the largest synthetic RS 3D dataset. SynRS3D comprises 69,667 high-resolution optical images that cover six different city styles worldwide and feature eight land cover types, precise height information, and building change masks. To further enhance its utility, we develop a novel multi-task unsupervised domain adaptation (UDA) method, RS3DAda, coupled with our synthetic dataset, which facilitates the RS-specific transition from synthetic to real scenarios for land cover mapping and height estimation tasks, ultimately enabling global monocular 3D semantic understanding based on synthetic data. Extensive experiments on various real-world datasets demonstrate the adaptability and effectiveness of our synthetic dataset and proposed RS3DAda method. SynRS3D and related codes will be available. |
 |
J. Xia, N. Yokoya, B. Adriano, and C. Broni-Bedaiko, ”OpenEarthMap: A benchmark dataset for global high-resolution land cover mapping,” Proc. WACV, 2023. Quick Abstract Abstract: We introduce OpenEarthMap, a benchmark dataset, for global high-resolution land cover mapping. OpenEarthMap consists of 2.2 million segments of 5000 aerial and satellite images covering 97 regions from 44 countries across 6 continents, with manually annotated 8-class land cover labels at a 0.25-0.5m ground sampling distance. Semantic segmentation models trained on the OpenEarthMap generalize worldwide and can be used as off-the-shelf models in a variety of applications. We evaluate the performance of state-of-the-art methods for unsupervised domain adaptation and present challenging problem settings suitable for further technical development. We also investigate lightweight models using automated neural architecture search for limited computational resources and fast mapping. The dataset will be made publicly available. |
 |
H. Chen, J. Song, C. Wu, B. Du, and N. Yokoya, ”Exchange means change: an unsupervised single-temporal change detection framework based on intra-and inter-image patch exchange,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 206, pp. 87-105, 2023. PDF Quick Abstract Abstract: Change detection is a critical task in studying the dynamics of ecosystems and human activities using multi-temporal remote sensing images. While deep learning has shown promising results in change detection tasks, it requires a large number of labeled and paired multi-temporal images to achieve high performance. Pairing and annotating large-scale multi-temporal remote sensing images is both expensive and time-consuming. To make deep learning-based change detection techniques more practical and cost-effective, we propose an unsupervised single-temporal change detection framework based on intra- and inter-image patch exchange (I3PE). The I3PE framework allows for training deep change detectors on unpaired and unlabeled single-temporal remote sensing images that are readily available in real-world applications. The I3PE framework comprises four steps: 1) intra-image patch exchange method is based on an object-based image analysis (OBIA) method and adaptive clustering algorithm, which generates pseudo-bi-temporal image pairs and corresponding change labels from single-temporal images by exchanging patches within the image; 2) inter-image patch exchange method can generate more types of land-cover changes by exchanging patches between images; 3) a simulation pipeline consisting of several image enhancement methods is proposed to simulate the radiometric difference between pre- and post-event images caused by different imaging conditions in real situations; 4) self-supervised learning based on pseudo-labels is applied to further improve the performance of the change detectors in both unsupervised and semi-supervised cases. Extensive experiments on two large-scale datasets covering Hongkong, Shanghai, Hangzhou, and Chengdu, China, demonstrate that I3PE outperforms representative unsupervised approaches and achieves F1 value improvements of 10.65% and 6.99% to the state-of-the-art method. Moreover, I3PE can improve the performance of the change detector by 4.37% and 2.61% on F1 values in the case of semi-supervised settings. Additional experiments on a dataset covering a study area with 144 km^2 in Wuhan, China, confirm the effectiveness of I3PE for practical land-cover change analysis tasks. |