Overview

Intelligent Imaging & Inverse Problems
Representative publications
 |
W. He, T. Uezato, and N. Yokoya,
”Interpretable deep attention prior for image restoration and enhancement,”
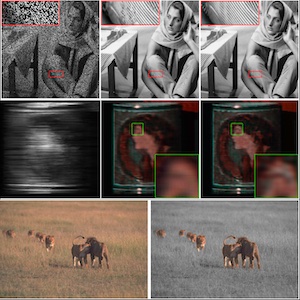
IEEE Transactions on Computational Imaging, vol. 9, pp. 185-196, 2023. PDF Quick Abstract Abstract: An interpretable deep attention prior that reveals nonlocal self-similarity through attention maps and stabilizes deep priors for inverse problems such as denoising, inpainting, and pansharpening. |
 |
X. Dong, N. Yokoya, L. Wang, and T. Uezato,
”Learning mutual modulation for self-supervised cross-modal super-resolution,”
Proc. ECCV, 2022. PDF Code Quick Abstract Abstract: A self-supervised cross-modal super-resolution framework that uses mutual modulation and cycle consistency to bridge modality gaps without paired HR/LR supervision. |
 |
T. Uezato, D. Hong, N. Yokoya, and W. He,
“Guided deep decoder: Unsupervised image pair fusion,”
Proc. ECCV (spotlight), 2020. PDF Supmat Code Quick Abstract Abstract: A unified, unsupervised framework for image pair fusion using an encoder–decoder guided deep decoder as an architectural prior, applicable across diverse fusion settings without training data. |
Multisource Fusion & Representation Learning
Representative publications
 |
W. Gan, N. Mo, H. Xu, and N. Yokoya, ”A comprehensive framework for 3D occupancy estimation in autonomous driving,” IEEE Transactions on Intelligent Vehicles, 2024. PDF Code Quick Abstract Abstract: The task of estimating 3D occupancy from surrounding view images is an exciting development in the field of autonomous driving, following the success of Birds Eye View (BEV) perception.This task provides crucial 3D attributes of the driving environment, enhancing the overall understanding and perception of the surrounding space. However, there is still a lack of a baseline to define the task, such as network design, optimization, and evaluation. In this work, we present a simple attempt for 3D occupancy estimation, which is a CNN-based framework designed to reveal several key factors for 3D occupancy estimation. In addition, we explore the relationship between 3D occupancy estimation and other related tasks, such as monocular depth estimation, stereo matching, and BEV perception (3D object detection and map segmentation), which could advance the study on 3D occupancy estimation. For evaluation, we propose a simple sampling strategy to define the metric for occupancy evaluation, which is flexible for current public datasets. Moreover, we establish a new benchmark in terms of the depth estimation metric, where we compare our proposed method with monocular depth estimation methods on the DDAD and Nuscenes datasets.The relevant code will be available in this https URL. |
 |
X. Dong and N. Yokoya,
”Understanding dark scenes by contrasting multi-modal observations,”
Proc. WACV, 2024. PDF Code Quick Abstract Abstract: A supervised multi-modal contrastive learning approach that improves semantic discriminability under low-light conditions, leveraging cross-modal and intra-modal contrast guided by class correlations. |
 |
H. Chen, N. Yokoya, C. Wu and B. Du,
”Unsupervised multimodal change detection based on structural relationship graph representation learning,”
IEEE Transactions on Geoscience and Remote Sensing, 2022. PDF Quick Abstract Abstract: A graph representation learning framework for unsupervised multimodal change detection, measuring modality-independent structural relationships and fusing difference cues for robust detection across heterogeneous sensors. |
3D / Digital Twins / Generative Intelligence
Representative publications
 |
Z. Liu, F. Liu, W. Xuan, and N. Yokoya,
”LandCraft: Designing the structured 3D landscapes via text guidance,”
Proc. AAAI, 2026. PDF Quick Abstract Abstract: LandCraft enables rapid authoring of production-ready landscapes from text via a coarse-to-fine pipeline: language/generative models infer abstract spatial/geographic representations, then procedural synthesis produces structurally consistent 3D scenes exportable to external engines. |
 |
W. Gan, F. Liu, H. Xu, and N. Yokoya, ”GaussianOcc: Fully self-supervised and efficient 3D occupancy estimation with Gaussian splatting,” Proc. ICCV, 2025. Project Page PDF Code Quick Abstract Abstract: We introduce GaussianOcc, a systematic method that investigates Gaussian splatting for fully self-supervised and efficient 3D occupancy estimation in surround views. First, traditional methods for self-supervised 3D occupancy estimation still require ground truth 6D ego pose from sensors during training. To address this limitation, we propose Gaussian Splatting for Projection (GSP) module to provide accurate scale information for fully self-supervised training from adjacent view projection. Additionally, existing methods rely on volume rendering for final 3D voxel representation learning using 2D signals (depth maps and semantic maps), which is time-consuming and less effective. We propose Gaussian Splatting from Voxel space (GSV) to leverage the fast rendering properties of Gaussian splatting. As a result, the proposed GaussianOcc method enables fully self-supervised (no ground-truth ego pose) 3D occupancy estimation in competitive performance with low computational cost (2.7 times faster in training and 5 times faster in rendering). The relevant code is available here. |
 |
Z. Liu, Z. Cheng, and N. Yokoya,
”Neural hierarchical decomposition for single image plant modeling,”
Proc. CVPR, 2025. Project Page Code Quick Abstract Abstract: A structured decomposition approach for single-image plant reconstruction, learning hierarchical representations that support diverse plant categories and yield practically usable 3D assets. |
 |
J. Song, H. Chen, W. Xuan, J. Xia, and N. Yokoya,
”SynRS3D: A synthetic dataset for global 3D semantic understanding from monocular remote sensing imagery,”
Proc. NeurIPS (spotlight), 2024. PDF Project Page Code Quick Abstract Abstract: SynRS3D provides large-scale synthetic EO imagery with semantics and height supervision, enabling scalable monocular 3D semantic understanding and bridging synthetic-to-real transfer. |
Vision–Language Models & Geo-AI Agents
Representative publications
 |
J. Wang, W. Xuan, H. Qi, Z. Chen, H. Chen, Z. Zheng, J. Xia, Y. Zhong, N. Yokoya, “CityVLM: Towards sustainable urban development via multi-view coordinated vision–language model,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 232, pp. 62–74, 2026. PDF Quick Abstract Abstract: Vision–language models (VLMs) have shown remarkable promise in Earth Vision, particularly in providing human-interpretable analysis of remote sensing imagery. While existing VLMs excel at general visual perception tasks, they often fall short in addressing the complex needs of geoscience, which requires comprehensive urban analysis across geographical, social, and economic dimensions. To bridge this gap, we expand VLM capabilities to tackle sustainable urban development challenges by integrating two complementary sources: remote sensing (RS) and street-view (SV) imagery. Specifically, we first design a multi-view vision–language dataset (CitySet), comprising 20,589 RS images, 1.1 million SV images, and 0.8 million question–answer pairs. CitySet facilitates geospatial object reasoning, social object analysis, urban economic assessment, and sustainable development report generation. Besides, we develop CityVLM to integrate macro- and micro-level semantics using geospatial and temporal modeling, while its language modeling component generates detailed urban reports. We extensively benchmarked 10 advanced VLMs on our dataset, revealing that state-of-the-art models struggle with urban analysis tasks, primarily due to domain gaps and limited multi-view data alignment capabilities. By addressing these issues, CityVLM achieves superior performance consistently across all tasks and advances automated urban analysis through practical applications like heat island effect monitoring, offering valuable tools for city planners and policymakers in their sustainability efforts. |
 |
J. Wang, W. Xuan, H. Qi, Z. Liu, K. Liu, Y. Wu, H. Chen, J. Song, J. Xia, Z. Zheng, and N. Yokoya, ”DisasterM3: A remote sensing vision-language dataset for disaster damage assessment and response,” Proc. NeurIPS, 2025. PDF Code Quick Abstract Abstract: Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities. |
 |
W. Xuan, J. Wang, H. Qi, Z. Chen, Z. Zheng, Y. Zhong, J. Xia, and N. Yokoya, ”DynamicVL: Benchmarking multimodal large language models for dynamic city understanding,” Proc. NeurIPS, 2025. PDF Code Quick Abstract Abstract: Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions. |
Trustworthy Multimodal AI
Representative publications
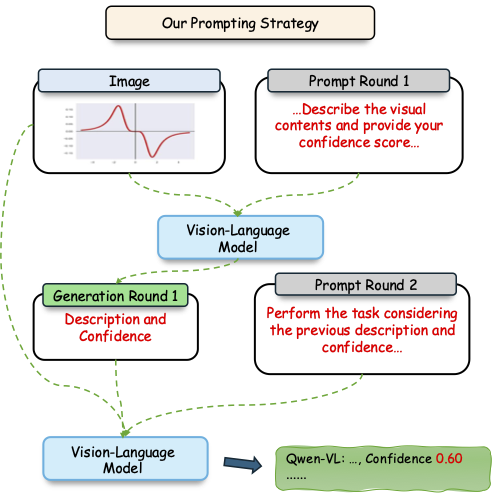 |
W. Xuan, Q. Zeng, H. Qi, J. Wang, and N. Yokoya,
”Seeing is believing, but how much? A comprehensive analysis of verbalized calibration in vision-language models,”
Proc. EMNLP (oral), 2025. PDF Quick Abstract Abstract: We evaluate verbalized confidence across VLM families and tasks, revealing miscalibration and showing that modality-specific reasoning improves confidence alignment. We propose a two-stage prompting strategy to improve calibration. |